# B + 树
# 什么是 B + 树
B + 树是在二叉查找树的基础上进行了改造:树中的节点并不存储数据本身,而是只是作为索引。每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。
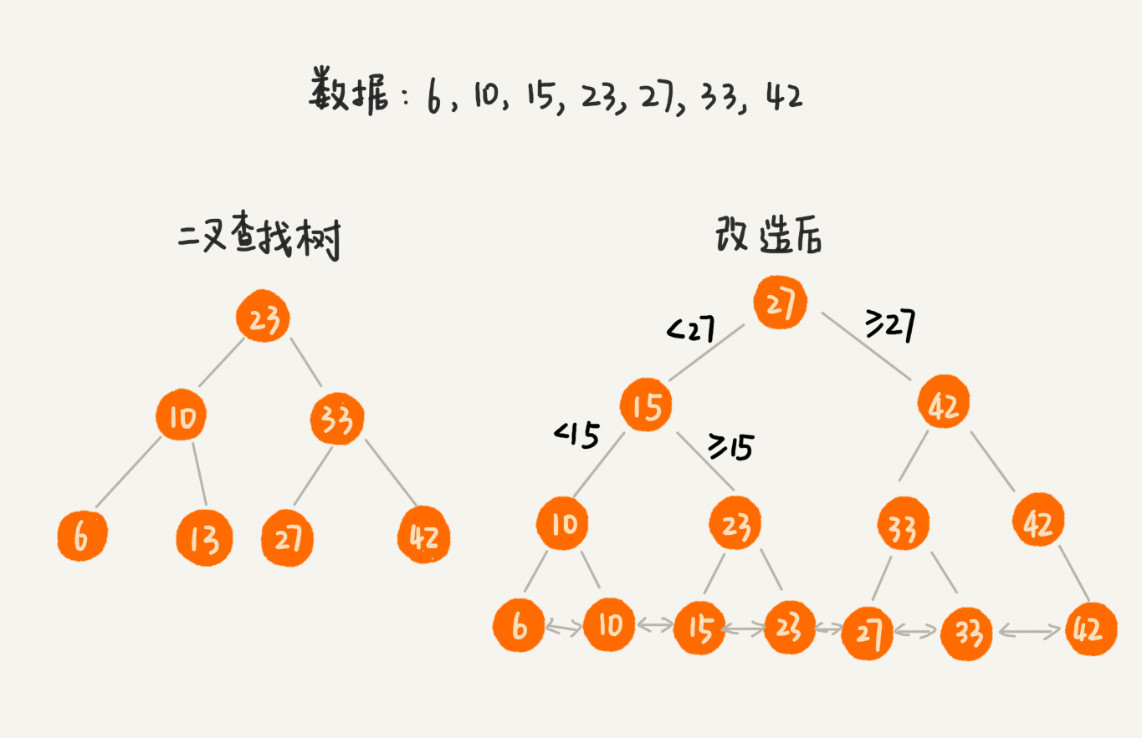
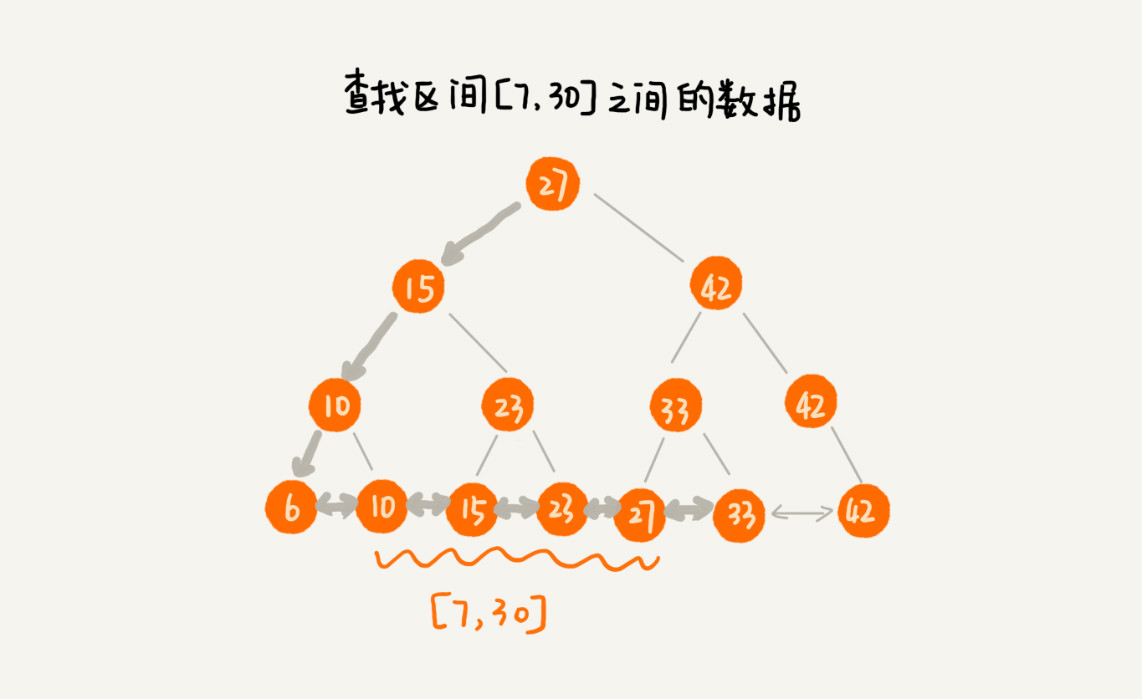
改造之后,如果我们要求某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。
但是,我们要为几千万、上亿的数据构建索引,如果将索引存储在内存中,尽管内存访问的速度非常快,查询的效率非常高,但是,占用的内存会非常多。
比如,我们给一亿个数据构建二叉查找树索引,那索引中会包含大约 1 亿个节点,每个节点假设占用 16 个字节,那就需要大约 1GB 的内存空间。给一张表建立索引,我们需要 1GB 的内存空间。如果我们要给 10 张表建立索引,那对内存的需求是无法满足的。如何解决这个索引占用太多内存的问题呢?
我们可以借助时间换空间的思路,把索引存储在硬盘中,而非内存中。我们都知道,硬盘是一个非常慢速的存储设备。通常内存的访问速度是纳秒级别的,而磁盘访问的速度是毫秒级别的。读取同样大小的数据,从磁盘中读取花费的时间,是从内存中读取所花费时间的上万倍,甚至几十万倍。
这种将索引存储在硬盘中的方案,尽管减少了内存消耗,但是在数据查找的过程中,需要读取磁盘中的索引,因此数据查询效率就相应降低很多。
二叉查找树,经过改造之后,支持区间查找的功能就实现了。不过,为了节省内存,如果把树存储在硬盘中,那么每个节点的读取(或者访问),都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。
我们前面讲到,比起内存读写操作,磁盘 IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作,也就是,尽量降低树的高度。那如何降低树的高度呢?
我们来看下,如果我们把索引构建成 m 叉树,高度是不是比二叉树要小呢?如图所示,给 16 个数据构建二叉树索引,树的高度是 4,查找一个数据,就需要 4 个磁盘 IO 操作(如果根节点存储在内存中,其他结点存储在磁盘中),如果对 16 个数据构建五叉树索引,那高度只有 2,查找一个数据,对应只需要 2 次磁盘操作。如果 m 叉树中的 m 是 100,那对一亿个数据构建索引,树的高度也只是 3,最多只要 3 次磁盘 IO 就能获取到数据。磁盘 IO 变少了,查找数据的效率也就提高了。
# 为什么需要 B + 树
关系型数据库中常用 B+ 树作为索引,这是为什么呢?
思考以下经典应用场景
- 根据某个值查找数据,比如
select * from user where id=1234。 - 根据区间值来查找某些数据,比如
select * from user where id > 1234 and id < 2345。
为了提高查询效率,需要使用索引。而对于索引的性能要求,主要考察执行效率和存储空间。如果让你选择一种数据结构去存储索引,你会如何考虑?
以一些常见数据结构为例:
- 哈希表:哈希表的查询性能很好,时间复杂度是
O(1)。但是,哈希表不能支持按照区间快速查找数据。所以,哈希表不能满足我们的需求。 - 平衡二叉查找树:尽管平衡二叉查找树查询的性能也很高,时间复杂度是
O(logn)。而且,对树进行中序遍历,我们还可以得到一个从小到大有序的数据序列,但这仍然不足以支持按照区间快速查找数据。 - 跳表:跳表是在链表之上加上多层索引构成的。它支持快速地插入、查找、删除数据,对应的时间复杂度是
O(logn)。并且,跳表也支持按照区间快速地查找数据。我们只需要定位到区间起点值对应在链表中的结点,然后从这个结点开始,顺序遍历链表,直到区间终点对应的结点为止,这期间遍历得到的数据就是满足区间值的数据。
实际上,数据库索引所用到的数据结构跟跳表非常相似,叫作 B+ 树。不过,它是通过二叉查找树演化过来的,而非跳表。B + 树的应用场景
# 参考资料
- 数据结构与算法之美